日期:2023-02-23 瀏覽:4251
分享:



ChatGPT從2022年11月問世至今,憑借著“上知天文,下知地理”的智能表現火速出圈,在內容生成、搜索引擎優化、編程協助、智能客服等領域展現出的巨大潛力,甚至引發了AI領域的新一輪技術升級與產業重構,國內外科技企業也紛紛加入這場人工智能的競賽。
就在不久前,北京市經濟和信息化局發布的《2022年北京人工智能產業發展白皮書》中明確提出“支持頭部企業打造對標ChatGPT的大模型,著力構建開源框架和通用大模型的應用生態。加強人工智能算力基礎設施布局。加速人工智能基礎數據供給。”
一場全球化、全領域的AI新浪潮已經來臨。
ChatGPT“狂飆”之路背后的存儲挑戰
ChatGPT是由美國人工智能研究實驗室OpenAI發布的一款生成式人工智能聊天機器人,是由人工智能技術驅動的自然語言處理工具,它能夠通過學習和理解人類的語言來進行對話,還能根據聊天的上下文進行互動,真正像人類一樣來聊天交流,甚至能完成撰寫郵件、視頻腳本、文案、翻譯、代碼,寫論文等任務。
ChatGPT使用的是GPT-3技術,即第三代生成式預訓練Transformer (Generative Pretrained Transformer 3),這是一種自回歸語言模型,所采用的數據量多達上萬億,主要使用的是公共爬蟲數據集和有著超過萬億單詞的人類語言數據集,對應的模型參數量也達到1,750億。
GPT-3.5則是GPT-3微調優化后的版本,比后者更強大。ChatGPT正是由GPT-3.5架構的大型語言模型(LLM)所支持的,使ChatGPT能夠響應用戶的請求,做出“類似人類的反應”。在此背后是參數量和訓練樣本量的增加,據了解,GPT-3.5包含超過1746億個參數,預估訓練一次ChatGPT至少需要約3640 PFlop/s-day的算力(即1PetaFLOP/s效率跑3640天)。
ChatGPT“無所不知”的背后除了考驗算力成本外,對數據存儲在速度、功耗、容量、可靠性等層面也提出了更高要求。
ChatGPT每個訓練步驟對存儲都有著嚴苛的要求:
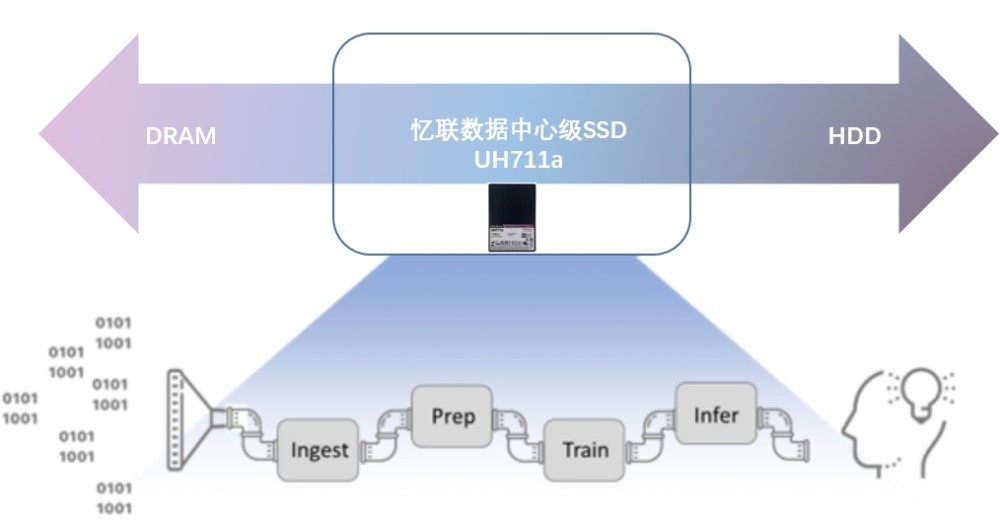
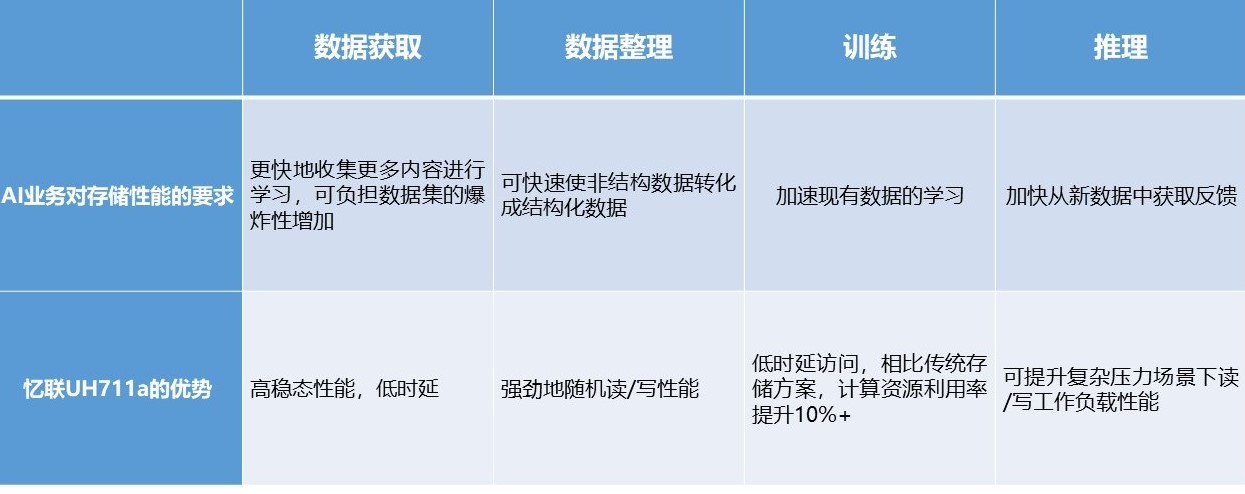
①數據獲取 …
因為ChatGPT的訓練需要大量的文本數據,所以需要先準備一個大規模的語料庫。語料庫可以來自各種渠道,例如維基百科、新聞網站、社交媒體等,并進行一定的預處理,例如去除特殊字符、分詞、轉換成小寫等。為了縮短收集數據進行分析所需的時間,需要同時從各渠道進行采集,該階段的重點在持續寫入,定期進行容量存儲的非易失性寫入,AI獲取的I/O配置文件通常是100%的順序寫入。
②數據整理 …
由于從各種渠道收集到的數據結構多種多樣,因此需要對獲取的數據進行整理后再進行訓練,例如對不完整的數據進行修復。針對不同屬性的數據,例如用于面部識別的圖像,必須進行歸一化;非結構化數據需要進行標記和注釋,便于深度學習算法的訓練,進而增強算法。最后將來源于不同渠道的數據進行合并,并轉換為目標格式。
這是一個不斷迭代的過程,也是具有高度并發性的混合工作負載過程,因為需要讀寫不同數量的數據,包括隨機和順序讀寫。讀寫比將根據攝入數據的準確性和達到目標格式所需的轉換程度而變化,極端情況下的工作負載可以接近50%的寫入,擁有高吞吐量、低延遲以及高QoS的存儲設備是減少數據整理時間的關鍵。
③訓練 …
ChatGPT的訓練使用了自監督學習(Self-supervised learning)的方法,即根據文本數據中的上下文關系來預測下一個單詞或字符。在訓練過程中,ChatGPT 使用了基于梯度下降的優化算法來調整模型參數,使得模型的預測結果更加接近實際結果。
這個階段非常耗費資源,因為涉及到從基于數據的預測到強化學習,再到神經網絡和基于運動模型的預測一系列重復的步驟,并不斷調節超參數與優化模型性能。大多使用的是隨機讀取和一些寫入用于檢查點設置,因此維持超快、高帶寬隨機讀取的存儲設備更有利于訓練,更快的讀取可以使有價值的訓練資源得到快速利用,而隨機性有助于提高模型的準確性。在此階段,減少I/O等待時間至關重要。
④推理 …
訓練結束后,將訓練好的模型執行推理,觀察并使用新的數據驗證推理結果是否符合預期。在推理階段同樣也需要大量讀取和具有極低響應時間的高性能存儲。推理可以部署在數據中心或邊緣設備中,實時邊緣部署不僅需要快速將已訓練好的模型讀入推理,還需要快速寫入攝取的數據以進行實時決策。隨著更多邊緣部署采用強化學習,對存儲設備性能的要求將更高。
AI浪潮之下,憶聯SSD能做什么
面對AI應用更嚴苛的存儲要求,憶聯UH711a作為一款數據中心級SSD,憑借在各方面出色的性能表現可應用在AI業務中的各個階段。
全場景調優,助推AI應用落地 …
UH711a面向數據中心級的讀密集場景、混合場景、寫密集場景等業務場景和各類IO pattern,可提供全面的性能、功耗調優。尤其在數據庫、塊存儲、對象存儲、海量存儲等對隨機IOPS性能高要求場景下UH711a的性能顯著。在與國內某互聯網客戶數據中心的合作中,通過使用憶聯UH711a,在混合讀寫滿負載業務場景下,存儲集群能耗比提升了12.5%。

尤其在隨機讀寫4K性能指標上,可提供更優的SSD能耗比,能滿足AI業務中高吞吐量的需求,使其可以更快地收集更多的數據,縮短從數據中獲取反饋的時間。如下圖所示,UH711a在數據中心業務隨機4K場景下IOPS per Watt 相比友商可提升42%。在數據中心級應用場景中可獲得12.5%的IOPS per Watt收益。
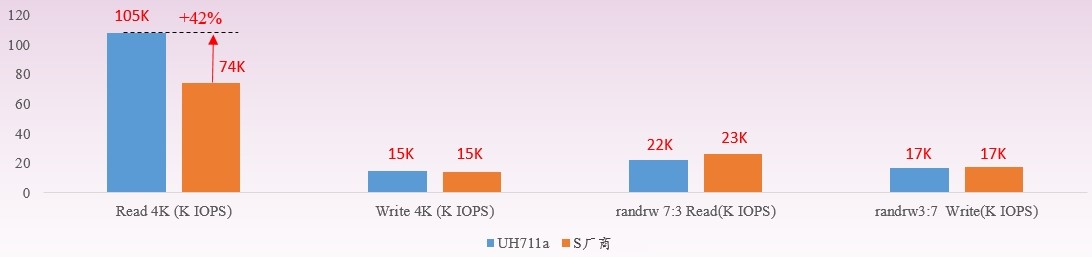
各類場景下的IOPS per Watt測試對比
SR-IOV技術加持,降本增效顯著 …
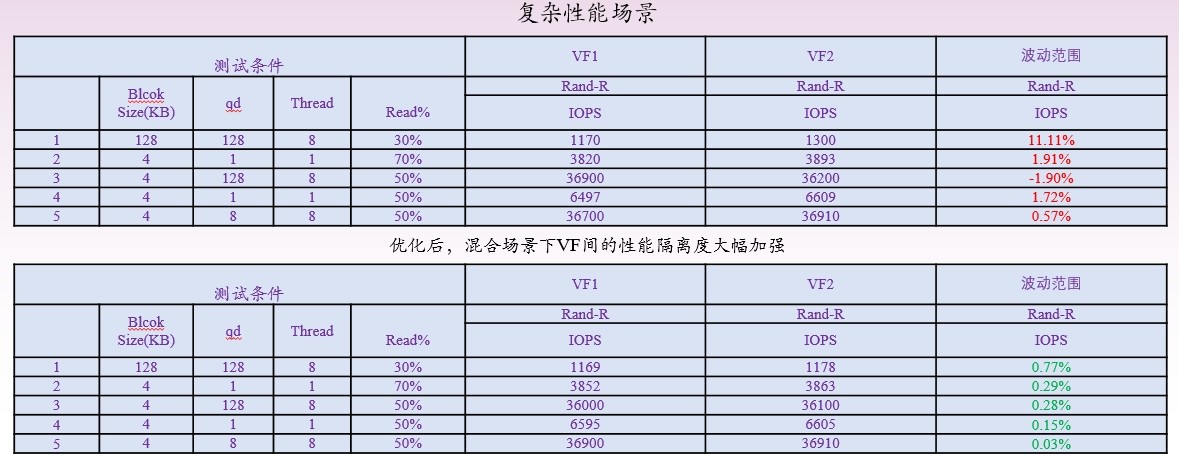
因SR-IOV技術可提供更好的密度性能、隔離性和安全性,目前已被數據中心廣泛采用。在面向AI應用進行部署與邏輯較為復雜的場景時,SR-IOV可為用戶提供安全、優質的AI計算資源。UH711a 通過使能SR-IOV技術優化云業務虛擬機場景,相比SPDK方案優勢顯著。憶聯采用的SR-IOV 2.0優化了各VF的性能隔離調度邏輯,使各VF間的性能隔離度更好,在純讀純寫場景下從原來的5%波動降低到3%;混合場景業務的波動從部分場景10%的波動優化到5%以內。
此外,UH711a基于QOS保障的SR-IOV特性,在虛擬化AI場景,配合NVIDIA GPU Directed Storage場景下提供高達7GBps、170M IOPS訪問能力,同時節約CPU算力10%,可減輕AI業務因數據持續增長的算力壓力。
例:
一臺12盤位服務器(128vCPU Core)使用憶聯SR-IOV特性,每片盤可節省2個vCPU Core(累計節省24vCPU Core);CPU價格按40$來計算,單臺服務器可節約CPU算力18.5%,釋放的CPU算力可額外提供存儲租用服務12個(24vCPU core / 2個vcpu綁定一個虛擬盤 )。
支持DIF特性,保障數據的可靠性 …
在機器學習中,若數據發生錯誤,研發人員可能花費大量時間進行查錯,拉高時間成本的同時也會影響數據集的質量,更有可能出現模型精度降低的風險。憶聯UH711a可支持DIF特性,能提升全鏈路數據保護能力。不僅與系統配合,實現端到端的保護,更能夠在盤內實現獨立的端到端保護機制,確保盤內整個通路的數據安全,從而為AI業務中多種極端場景下的正常運維提供雙重保護。

憶聯UH711a還支持多種DIF配置,512+8、4K+8、4K+64,支持從應用到Flash的端到端數據保護,并能有效杜絕data replacement故障發生的可能,保障數據的完整性,助力AI模型的訓練與推理能順利完成。
優異的QoS,提升用戶體驗 …
憶聯UH711a采用了One Time Read技術,即結合介質分組管理、最優讀電壓實時追蹤技術,對每個IO進行最優應答策略設計。可增強盤片的QoS競爭力,99.9% IO讀一次成功,延時小于350us,能縮短在AI訓練與推理時的實時決策時間,并提升盤片QoS能力與延長End of Life。

在前臺最優響應用戶IO:
·以IO PPN信息,查詢最優電壓分組管理表;
·同時獲取介質狀態信息(Open \ Close \ Affected WL等);
·根據介質狀態和分組表記錄最優電壓,采用預先設計的最優應答策略讀取數據,最大程度縮短每個IO的響應延時。
在后臺進行智能維護:
·依據大數據分析,對介質進行智能分組管理;
·關鍵事件觸發,對介質狀態進行更新維護;
·根據介質狀態、實時巡檢,依托最優電壓跟蹤IP,對電壓分組管理表進行更新,保障電壓準確度。
面向未來,憶聯推動數據存儲再進化
據報道,OpenAI已建立了一個比ChatGPT更先進的大型語言模型GPT-4,更有傳聞稱其可以通過圖靈測試,這意味人工智能將再次邁向新的臺階。憶聯作為科技浪潮中的一員將堅持以創新為驅動,為人工智能的部署與優化提速。
產品層面:針對AI業務場景及IO pattern,對SSD的高穩態性能、虛擬化與高能耗提出的更高需求,憶聯將積極研發更具創新力與更高性能的存儲產品,從產品形態、性能、深度定制化特性等多維度豐富產品矩陣。
解決方案層面:聯合上下游伙伴探索先進技術,面向云計算、數據中心、服務器、運營商等關鍵行業打造場景化的存儲解決方案,并積極推動產品與基礎軟硬件的兼容適配,加快人工智能部署升級。

地址:深圳市南山區記憶科技后海中心B座19樓
電話:0755-2681 3300
郵箱:support@unionmem.com